


By Thomas Thiery – June 26th, 2025
Thanks to Léonard Monsaingeon, Caspar Schwarz-Schilling, Julian Ma, Anders Elowsson, Raúl Kripalani, Yann Vonlanthen, Csaba Kiraly and Marco Munizaga for the great feedback and comments on earlier versions of this post.
TL;DR
Classic Gossipsub floods the network with many duplicates, wasting bandwidth. Wasserstein-Fisher-Rao (WFR) Gossip addresses this by treating propagation as an optimal-transport problem: nodes forward messages preferentially along lower-latency links. In simulations with 10,000 nodes, WFR-Gossip reduced bandwidth usage by ~50% and improved latency by 40%, maintaining over 95% network coverage.
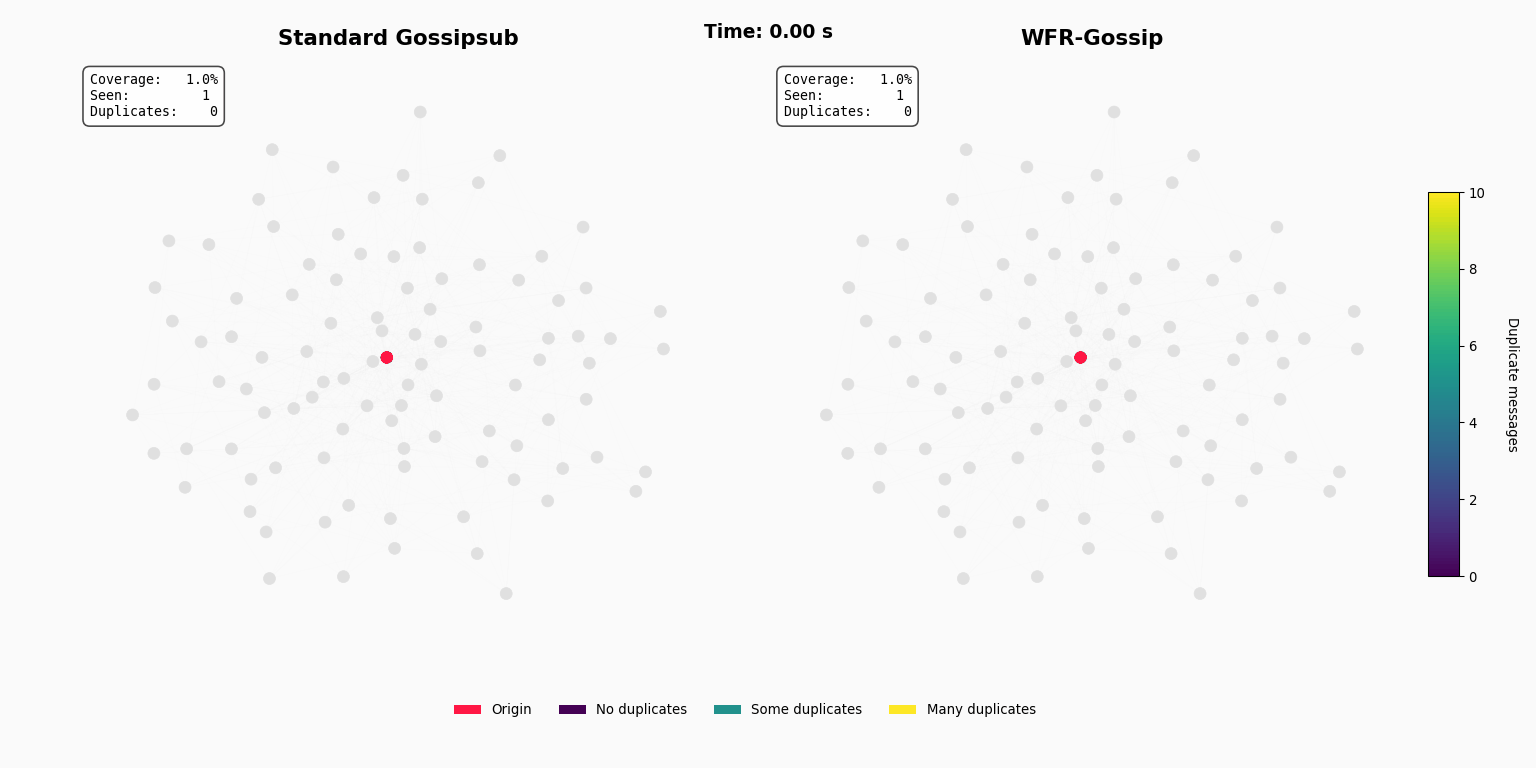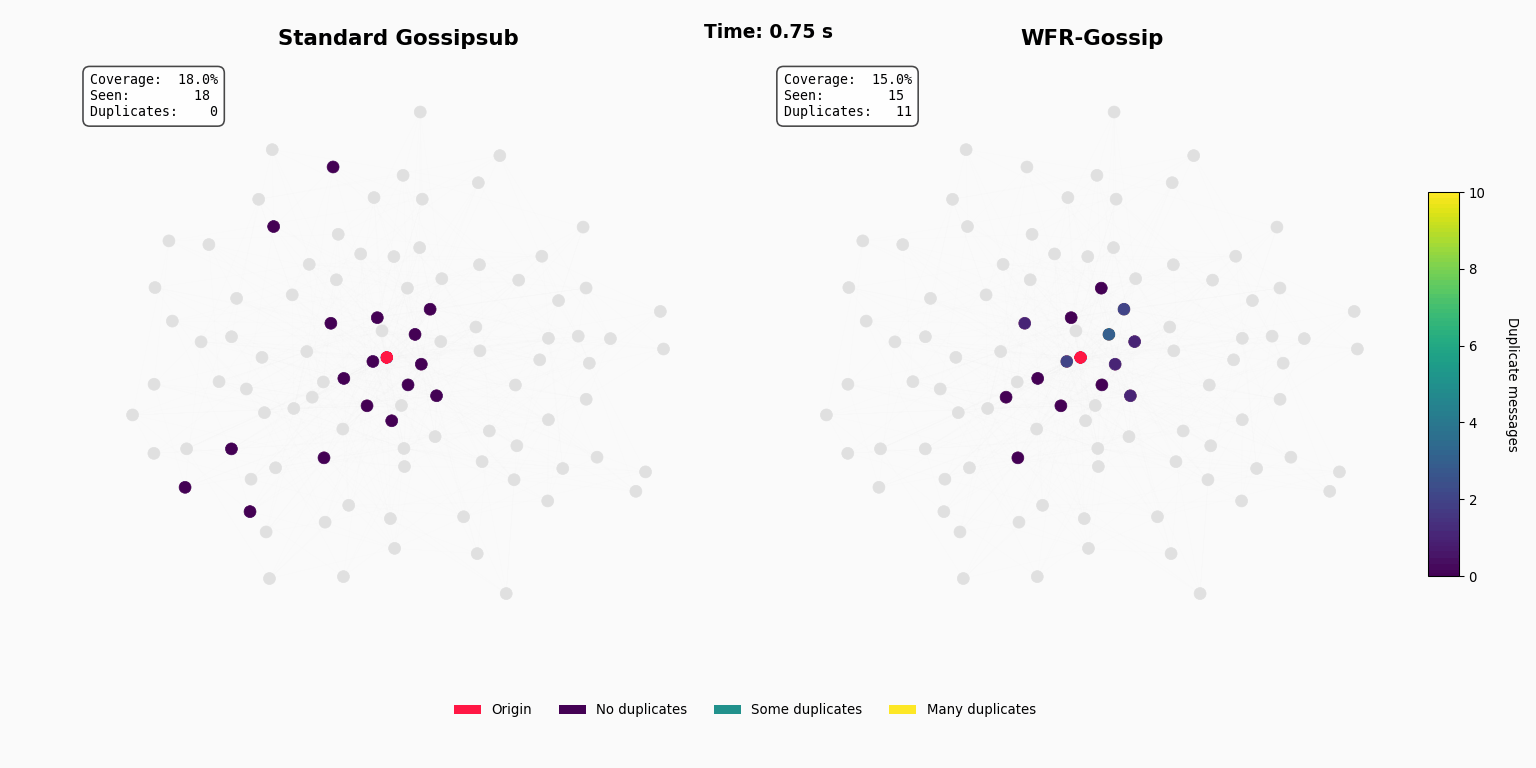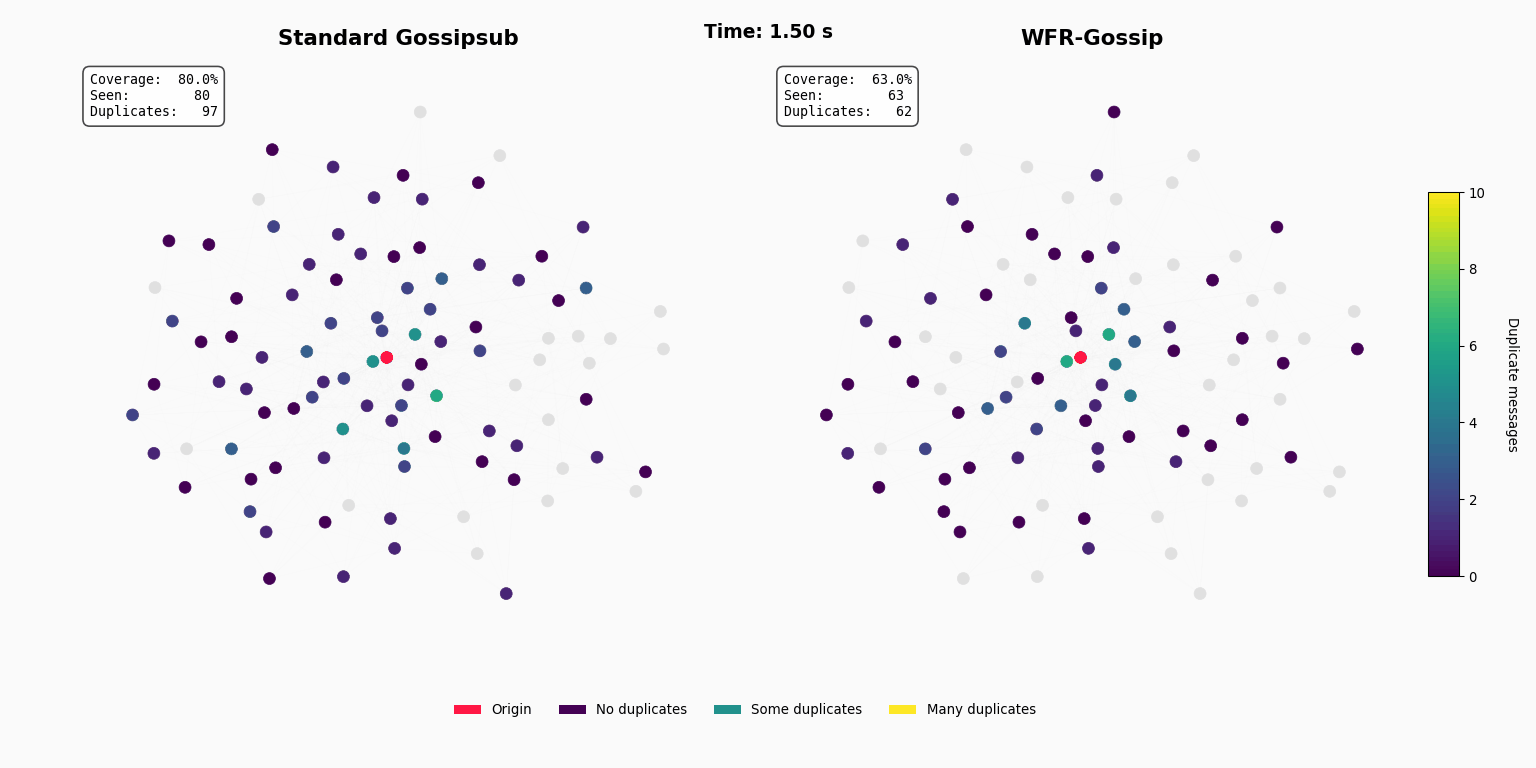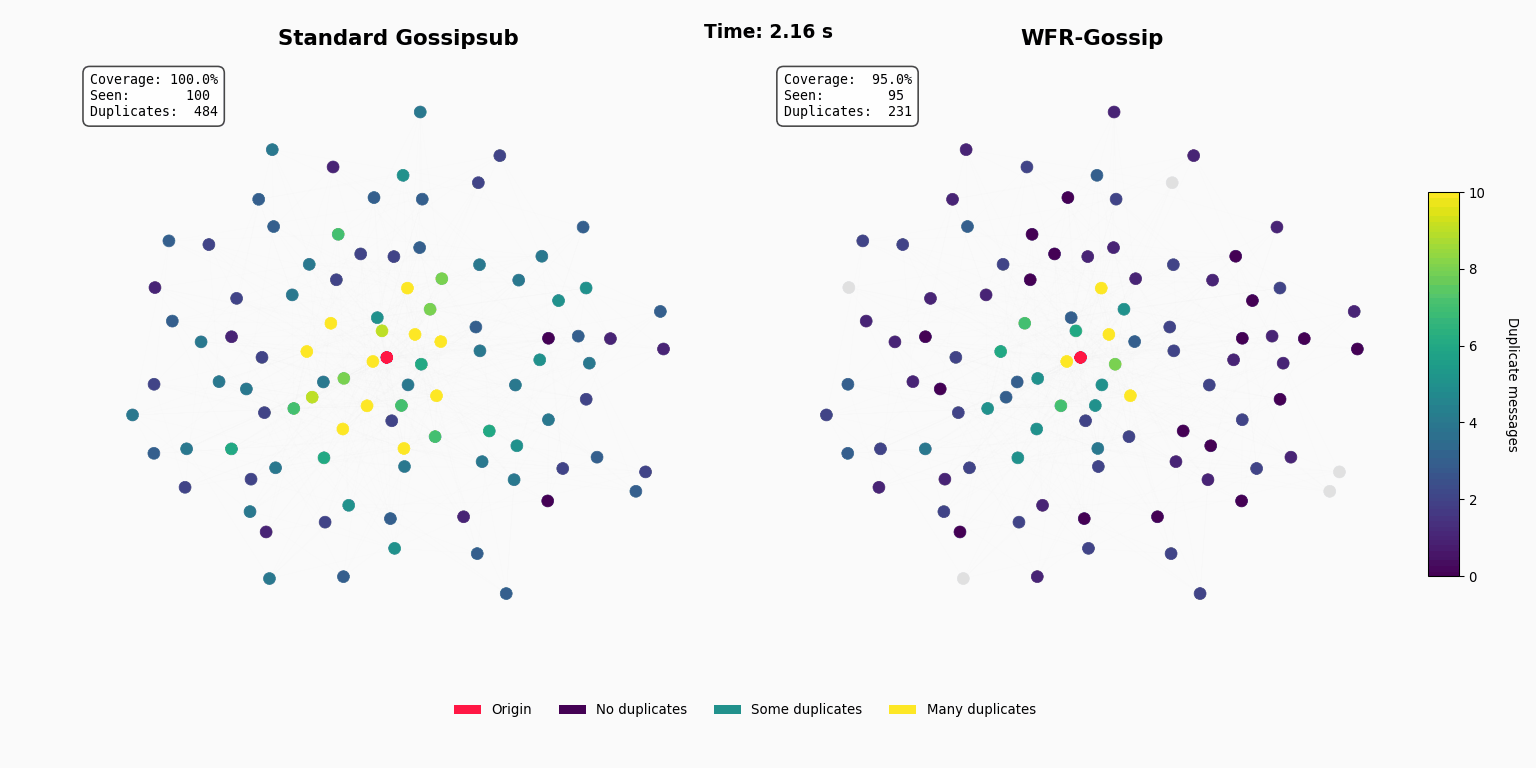
Introduction
Gossipsub works on a simple and clever principle: for any given topic, each node maintains a small set of peers called a “mesh”. When a node receives a new message, it forwards the full message to all peers in its mesh (mesh = 8 on Ethereum). To discover messages it might have missed, it gossips metadata (i.e., “I have seen message X”) to other peers outside the mesh. This is great for redundancy and censorship resistance. But it has a hidden cost.
The cost is inefficiency. In a dense network, this design leads to a large number of duplicate messages. While real-world data from the network shows that a typical node sees a median of 5 duplicates for a beacon block, the tail-end experience is what reveals the strain: the unluckiest 5-10% of nodes receive the same block 12 to 16 times or more (see this post for more details). For a long time, this was an acceptable trade-off. Bandwidth was cheap enough, and the protocol worked. But in today’s world we need to propagate increasingly large volumes of data over shorter timespans. Bandwidth is no longer just a hidden cost and its inefficiency has become a primary bottleneck to scaling.
The question then becomes: can we design a “smarter” gossip protocol while retaining the decentralization and robustness properties of Gossipsub? It turns out we can, and the answer lies in a surprisingly applicable corner of mathematics: optimal transport.
From randomness to physics
The core limitation of current thinking around p2p networks is to consider gossip as a fundamentally random process. A node forwards to its peers, those peers forward to theirs, and eventually, everyone gets the message.
Instead of a communications problem, we can reframe it as a physical distribution problem.
Imagine a message is a pile of sand, initially located at a single node. The goal is to get one grain of that sand to every other node in the network. The “cost” of moving sand between any two nodes is the latency of their connection. What is the most efficient way to achieve this distribution?
This is exactly the question that the field of optimal transport has been studying for over 200 years. It provides a mathematical framework for finding the minimum-cost plan to transform one distribution of mass (the entire pile of sand on node A) into another (one grain of sand on every node).
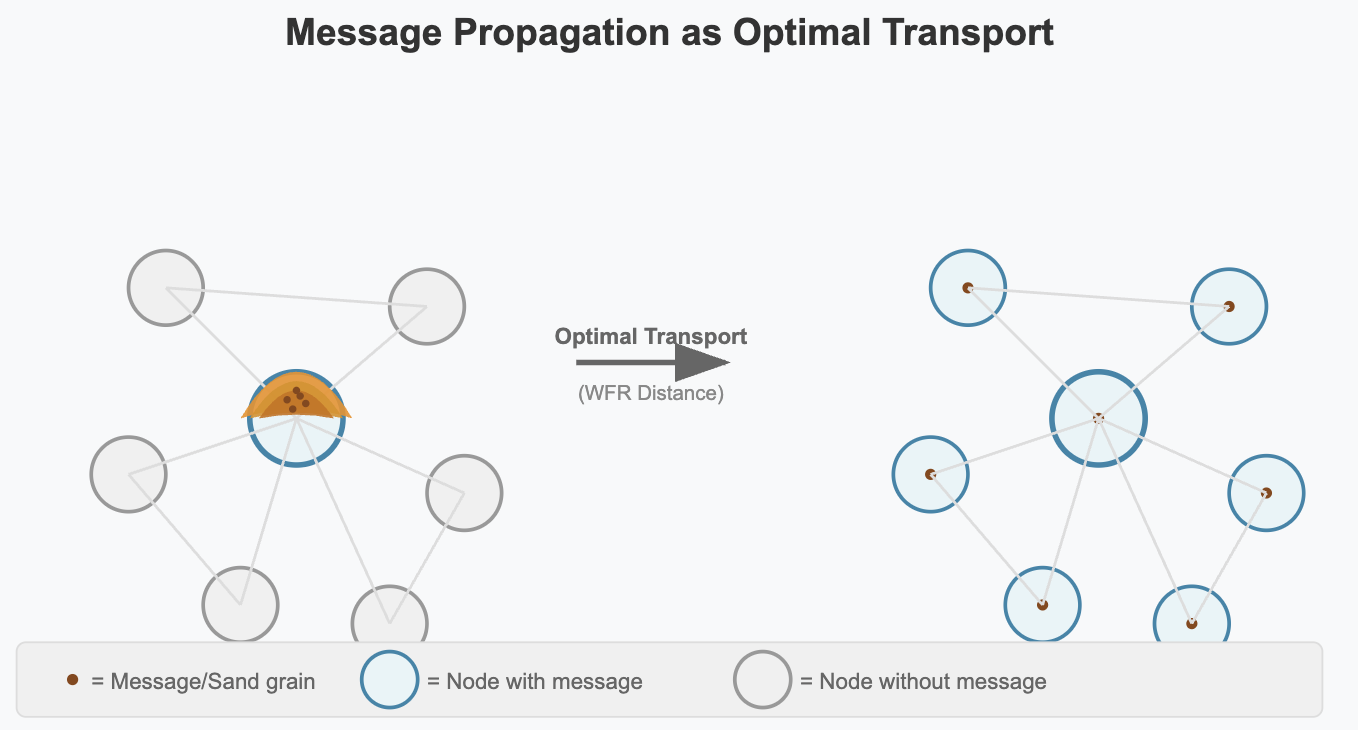
This suggests that instead of forwarding messages based on fixed, random-ish rules to ensure resilient propagation, nodes could make decisions based on minimizing a global transport cost. However, a key piece of the puzzle is missing. Standard optimal transport assumes the amount of sand is conserved, and gossip protocols constantly create copies and destroy duplicates.
Unbalanced optimal transport: using the Wasserstein-Fisher-Rao (WFR) distance
This is where a more modern tool comes in: unbalanced optimal transport. Specifically, a metric known as the Wasserstein-Fisher-Rao (WFR) distance.
In a nutshell, WFR can calculate the most efficient path between two states when you are allowed to not only move mass but also create it and annihilate it, each with an associated cost.
This maps perfectly to scenarios encountered in p2p networks:
- Moving mass = Forwarding a message over a link with a certain latency.
- Creating mass = A node duplicating a packet to forward it.
- Annihilating mass = A node receiving a duplicate and dropping it (deduplication).
Now we have a mathematical tool that can model the physical reality of a gossip network. The goal of WFR-Gossip can be stated formally: at every step, each node should act in a way that brings the global state of message distribution down the “steepest path” toward the optimal, uniform state, as measured by this WFR metric. We can think of this process as a gradient flow.
The total “energy” of the system at any time t can be described by an equation that looks like this:
All this says is: the next state of the network (μᵗ⁺¹) should be the one (ν) that minimizes the sum of two things: the WFR cost of getting from the current state to the next one, plus some penalty (F(ν)) for not yet having reached the goal where everyone has the message.
Making it practical for decentralized settings
This all works nicely, but it would require a central computer with a god’s-eye-view of the network to calculate the global gradient flow. The JKO splitting scheme tells us that this complex global optimization problem can be approximated by a simple, decentralized heuristic that relies only on information a node already has.
A real Ethereum node knows two crucial things:
- The round-trip time (RTT) to each of its direct peers, which it learns via the standard ping protocol.
- When it receives a message, it knows who sent it and its RTT to that sender.
Using only this local information, we can translate the complex “gradient flow” into a simple, two-phase forwarding rule that balances robustness with efficiency. At every hop, a node executes this hybrid heuristic:
Robust Forwarding: To ensure the message propagation never dies out prematurely, a node always sends the message to a small number of peers chosen at random (e.g., the Drobust= 3 random peers). This guarantees multiple independent paths so propagation can’t stall.
Efficient Filtering: For its other candidate peers (e.g., the remaining 5 out of 8 candidate peers), the node applies a smart filter. It will only forward the message if the outbound link to that peer is faster than the inbound link the message just arrived on. This simple “downhill” rule (latency_out < latency_in) effectively prunes redundant forwards along slower paths, thus saving bandwidth. Importantly, for any nodes missed by this efficient push, the existing lazy gossip of metadata (IHAVE messages) acts as a backstop, ensuring eventual 100% network coverage.
Local “downhill” decision in practice
Every libp2p node already tracks a fresh RTT for each peer, refreshed every 10-15 s by the ping protocol. When the first full copy of a message arrives, the node records the RTT of the link it came over (latency_in). It then forwards the message only to peers whose stored RTT (latency_out) is strictly smaller than latency_in (optionally minus a 1-2 ms safety margin). This single comparison – “is this link faster than the one just used?” – implements the downhill rule; no global view or extra signalling is required.
In the near future, we intend to further enhance the accuracy and responsiveness of this heuristic by leveraging QUIC’s native RTT observations instead of relying solely on periodic pings (h/t Raul). QUIC continuously monitors RTT as part of its transport-layer protocol, enabling nodes to access near-instantaneous latency data without additional overhead. This integration will substantially refine WFR-Gossip’s latency-informed decision-making, improving efficiency and responsiveness in real-world network conditions.
Here’s a simple example to illustrate this logic: A message starts at A and is sent to B. Imagine three nodes in a line: A --(10ms)--> B --(20ms)--> C.
- Gossipsub:
Breceives the message and forwards it to every other peer in its mesh (up to eight), even if some of those links are much slower. (It does skip sending the message back on the same connection toA, but duplicates can still reachAand many other peers through slower alternate routes.) - WFR-Gossip:
Breceives the message fromA(latency_in=10ms) and will only forward toCbecause its connection is slower (latency_out=20ms), correctly stopping the redundant backward message toAsince10msis not less than10ms.
This hybrid approach is a practical algorithm that achieves the same goal as the abstract math: each node, by following these local rules, acts as an agent in a collective process that pushes the message distribution toward the optimal state with minimal wasted effort.
Simulations: Method and results
To test this theory in a controlled environment, we used a discrete-event simulation to construct a realistic P2P network topology of 10,000 nodes using a scale-free graph model with mesh=8. Each link in this virtual network is assigned a latency based on a geographic distance model, creating a consistent “cost” landscape.
We simulated a single block propagation event, first using the rules of standard Gossipsub (forwarding to a random mesh of ~8 peers) to establish a baseline. We then ran a series of experiments for WFR-Gossip, iterating through our Drobust parameter from 1 to 8 to measure the trade-off between guaranteed forwarding (robustness) and smart filtering (efficiency).
The results illustrate the strengths of this new approach:
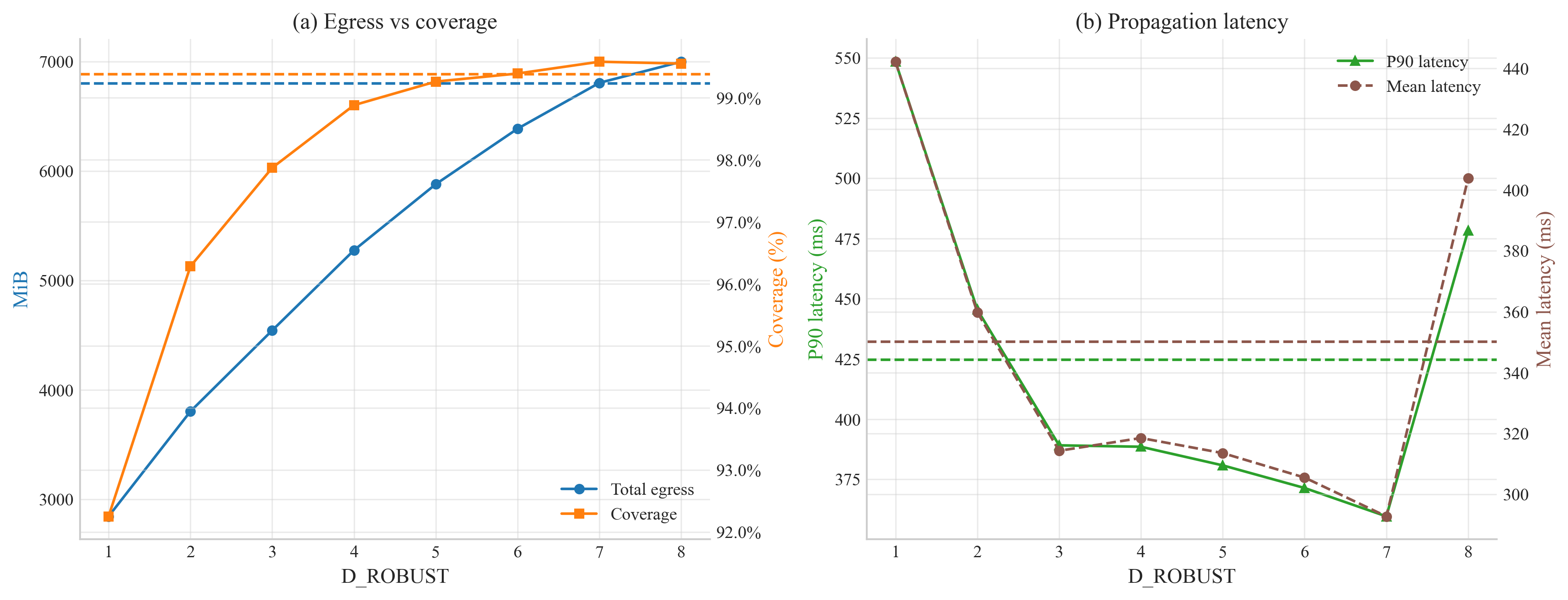
Figure 1. Performance trade-off of WFR-Gossip as a function of the robustness parameter Drobust. Panel A. Solid blue line (left y-axis) = total network egress per block (MiB) under WFR-Gossip; solid orange line (right y-axis) = network coverage (% first-receivers). Dashed blue and orange horizontals denote, respectively, the egress and coverage baselines of Gossipsub. Panel B. Solid green triangles (left y-axis) = 90th-percentile first-arrival latency; dashed-circle magenta line (right y-axis) = mean first-arrival latency. Corresponding dashed horizontals give the Gossipsub baselines. Error bars (where visible) show ±1 σ across five independent Monte-Carlo simulations.
As expected, increasing Drobust directly improves network coverage at the expense of higher bandwidth usage. With the updated simulation data, a clear “sweet spot” emerges around Drobust = 3, achieving approximately 98% coverage while significantly reducing total bandwidth usage by about one-third compared to the Gossipsub baseline (4.5 GiB vs. 6.8 GiB).
The slightly sub-100% network coverage observed at lower Drobust values (particularly below 4) results from WFR-Gossip’s strict yet efficient eager-push heuristic. In practice, this gap would be addressed by the existing lazy gossip of metadata (IHAVE messages), ensuring eventual full coverage. This combination would provide the protocol with the bandwidth efficiency of WFR-Gossip’s eager push alongside the full-coverage guarantees inherent in Gossipsub’s lazy gossip backstop.
Interestingly, WFR-Gossip demonstrates consistently lower propagation latencies than Gossipsub for Drobust values of 3 and above. This reduction in latency is primarily achieved by substantially decreasing the number of redundant message duplicates, alleviating network congestion. For instance, at Drobust = 7, WFR-Gossip attains over 99.5% coverage while matching Gossipsub’s bandwidth usage and reducing the 90th-percentile latency by approximately 15%.
Here are the results for some metrics to highlight key differences between Gossipsub and WFR-Gossip for Drobust from 1 to 8. You can find the code used for the simulation here.
| Protocol | Drobust | Coverage (%) | P90 Time (ms) | Mean Time (ms) | Min Time (ms) | Std Time (ms) | Mean Hops | P90 Hops | Mean Duplicates | Total Egress (MB) | Wasted Bandwidth (MB) |
|---|---|---|---|---|---|---|---|---|---|---|---|
| Gossipsub | N/A | 99.38 | 424.67 | 350.19 | 0.00 | 62.65 | 5.71 | 7.00 | 6.75 | 6801.68 | 5928.31 |
| WFR-Gossip | 1 | 92.25 | 548.39 | 442.21 | 0.00 | 84.62 | 7.78 | 10.00 | 2.31 | 2843.09 | 2032.38 |
| WFR-Gossip | 2 | 96.28 | 445.49 | 359.79 | 0.00 | 70.39 | 7.53 | 10.00 | 3.36 | 3802.50 | 2956.38 |
| WFR-Gossip | 3 | 97.87 | 389.15 | 314.30 | 0.00 | 60.89 | 6.53 | 8.00 | 4.19 | 4543.15 | 3683.06 |
| WFR-Gossip | 4 | 98.88 | 388.56 | 318.49 | 0.00 | 58.10 | 6.76 | 9.00 | 5.01 | 5276.34 | 4407.36 |
| WFR-Gossip | 5 | 99.26 | 380.83 | 313.53 | 0.00 | 56.21 | 6.29 | 8.00 | 5.70 | 5880.32 | 5008.01 |
| WFR-Gossip | 6 | 99.39 | 371.44 | 305.49 | 0.00 | 55.04 | 6.38 | 8.00 | 6.27 | 6387.71 | 5514.26 |
| WFR-Gossip | 7 | 99.58 | 359.66 | 292.73 | 0.00 | 56.28 | 6.06 | 8.00 | 6.75 | 6806.78 | 5931.65 |
| WFR-Gossip | 8 | 99.55 | 478.37 | 403.90 | 0.00 | 61.64 | 5.83 | 8.00 | 6.97 | 6999.61 | 6124.75 |
Comparison with existing approaches
WFR-Gossip vs. Gossipsub’s peer scoring
Gossipsub v1.1 optimizes mesh quality through peer scoring parameters like p1, which reward peers for prompt message delivery. However, this improvement occurs only through gradual mesh adjustments: each message is still forwarded to all eight mesh peers, without real-time efficiency considerations. In contrast, WFR-Gossip proactively makes latency-informed forwarding decisions for each individual message. Our simulations show that, given the same peer connections, WFR-Gossip significantly reduces redundant message propagation, lowering both latency and bandwidth usage.
WFR-Gossip vs. greedy latency-based routing
Pure latency-based routing methods, which forward messages solely along the fastest available paths, can inadvertently create bottlenecks, local minima, and vulnerabilities to manipulated latency measurements. WFR-Gossip addresses these problems through its hybrid heuristic: the robustness parameter (Drobust) guarantees multiple independent propagation paths to prevent stalls, while the “downhill” latency filter selectively prunes redundant, slower routes. Additionally, integration with Gossipsub’s existing peer scoring mitigates the risk of latency manipulation by malicious peers.
WFR-Gossip vs. structured topology-aware protocols
Topology-aware protocols, such as Dynamic Optimal Graph (DOG), require explicit construction and maintenance of structured network topologies, adding complexity, overhead, and challenges in handling node churn. WFR-Gossip avoids these overheads entirely by leveraging existing randomized network connections and lightweight local RTT measurements, making it simpler and inherently more resilient.
However, WFR-Gossip’s simplicity has trade-offs. By preferentially pruning slower links, nodes with lower bandwidth or higher latency may rely more heavily on the slower lazy gossip fallback (IHAVE/IWANT), potentially increasing message latency. Its dependence on local RTT measurements also introduces susceptibility to RTT manipulation attacks. Both issues can be mitigated through careful parameter tuning and Gossipsub’s peer-scoring mechanisms, but we need to keep this in mind when testing WFR-Gossip in realistic or adversarial network conditions.
WFR-Gossip vs. reactive Gossipsub extensions (CHOKE, IDONTWANT)
Extensions like CHOKE and IDONTWANT retrospectively manage redundancy by limiting duplicate message propagation after duplication is detected. WFR-Gossip instead proactively avoids duplication by making informed forwarding decisions upfront, based on local latency (RTT) information. Thus, WFR-Gossip can complement these existing reactive mechanisms, and offer improved bandwidth utilization, reduced latency, and overall improved performance.
Future work and open questions
- Deploy WFR‑Gossip behind a feature flag in clients (e.g., devnets/perfnets), and libp2p simulators to gather metrics from more realistic networks
- Dive deeper into interactions between WFR-Gossip and recent Gossipsub optimizations (
IWANT,IDONTWANT,CHOKE) - Explore other “proactive” mechanisms that improve efficiency without sacrificing robustness/resilience




