Ethereum Bytecode and Code Chunk Analysis
Code chunking is a strategy for breaking up bytecode into smaller chunks, which helps reduce witness size. However, this approach is only effective if a relatively small portion of the bytecode is accessed during execution. This analysis explores byte and chunk access patterns to evaluate the utility of code chunking.
Methodology
The complete repository which includes the data collection and analysis code can be found here.
Analysis
Key Dataset Statistics
- Block range: 15537394 (The Merge)–22000000
- Block Count: 100898 (spreaded evenly across the block range)
- Total contract interactions: 19,934,701
- Min. unique contracts interacted with per block: 1
- Median unique contracts interacted with per block: 187
- Max. unique contracts interacted with per block: 659
- Total unique contracts interacted with: 1,220,017
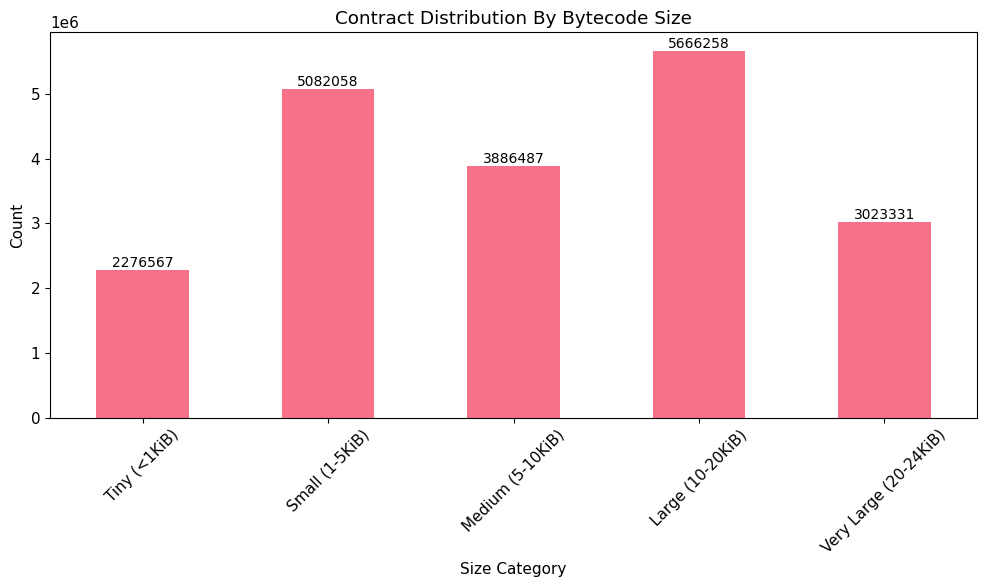
Bytes Access Patterns
This section examines the proportion of bytecode accessed during contract execution:
Bytes Accessed Ratio = bytes accessed / total bytecode size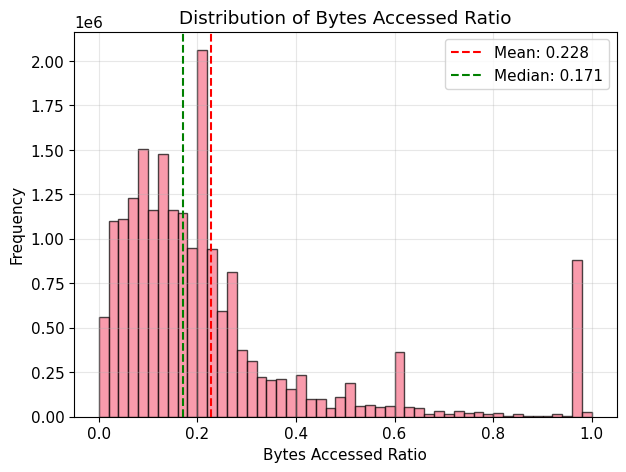
Core Finding: On average, only 22.8% of the contract bytecode was accessed in a block.
Detailed Insights:
- Median proportion accessed: 17.1%
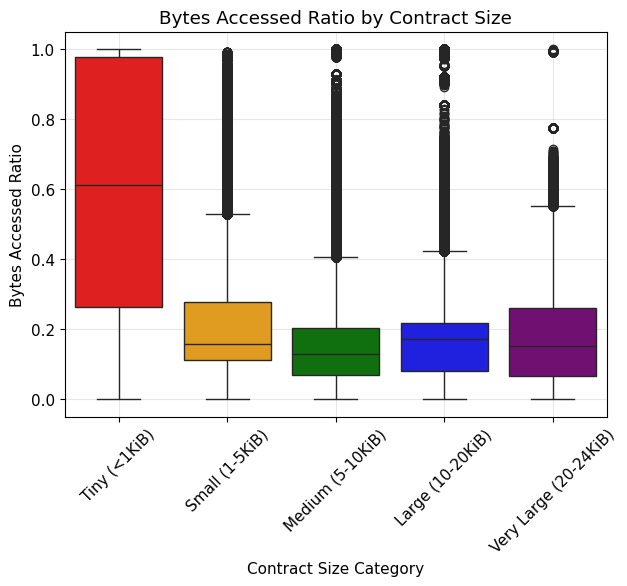
- By contract size:
- Tiny (<1 KiB): avg 62.9%, median 61.2%
- Small (1–5 KiB): avg 21.6%, median 15.8%
- Medium (5–10 KiB): avg 15.0%, median 13.0%
- Large (10–20 KiB): avg 16.5%, median 17.3%
- Very Large (20–24 KiB): avg 16.1%, median 15.1%
Interpretation: For contracts larger than 1 KiB, only a small fraction of the bytecode is accessed. Contracts under 1 KiB tend to have more of their bytecode accessed. This is expected, as small contracts usually contain fewer functions that are repeatedly invoked.
Chunk Access Patterns
Referencing EIP-2926 as a code chunking solution, we split the contract bytecode into 31-byte chunks and assess the proportion of 31-byte chunks accessed:
Total number of chunks = bytecode size / 31Chunks Accessed Ratio = chunks accessed / total number of chunks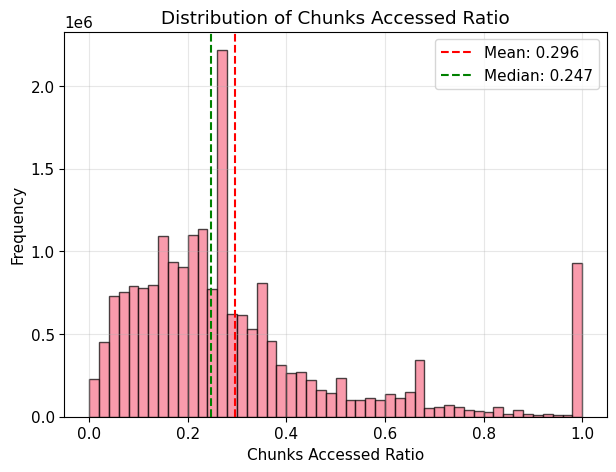
Core Finding: On average, only 29.6% of 32-byte chunks were accessed in a block.
Detailed Insights:
- Median proportion accessed: 24.7%
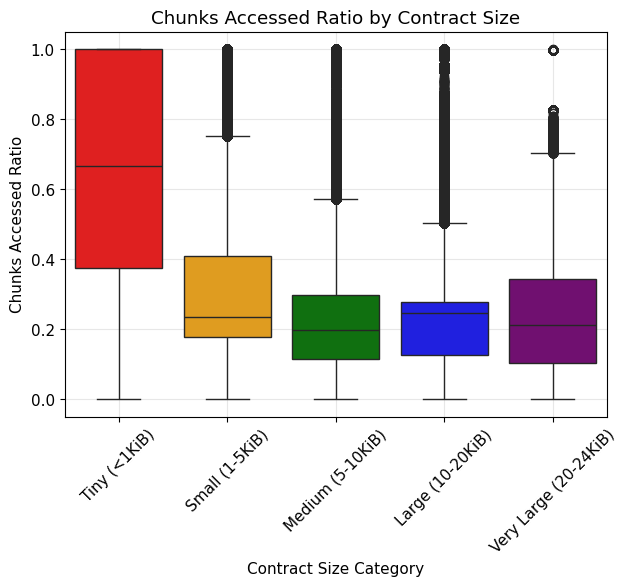
- By contract size:
- Tiny (<1 KiB): avg 69.1%, median 66.7%
- Small (1–5 KiB): avg 30.8%, median 23.5%
- Medium (5–10 KiB): avg 22.0%, median 19.6%
- Large (10–20 KiB): avg 22.2%, median 24.5%
- Very Large (20–24 KiB): avg 21.7%, median 21.1%
Interpretation: The results are similar to the bytes accessed ratio. Chunk access is also low for contracts over 1 KiB. However, the overall chunk accessed ratios are slightly higher than byte accessed ratios, suggesting that not all bytes in the accessed chunks were used.
Chunks Efficiency
In this section, we explore how efficient chunks are, i.e., how many bytes in the chunks are actually used:
Chunks Efficiency = bytes accessed / (chunks accessed * 31)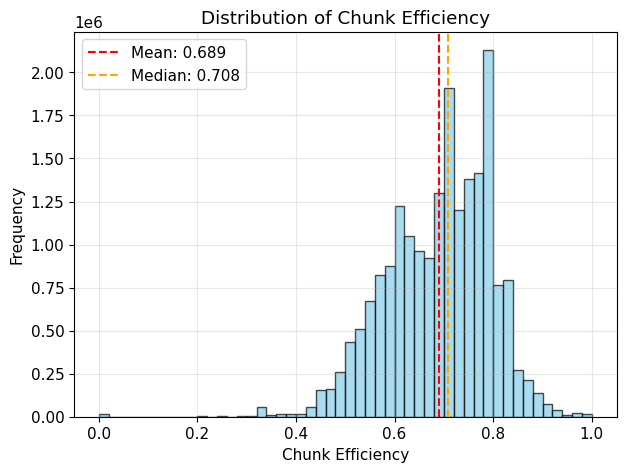
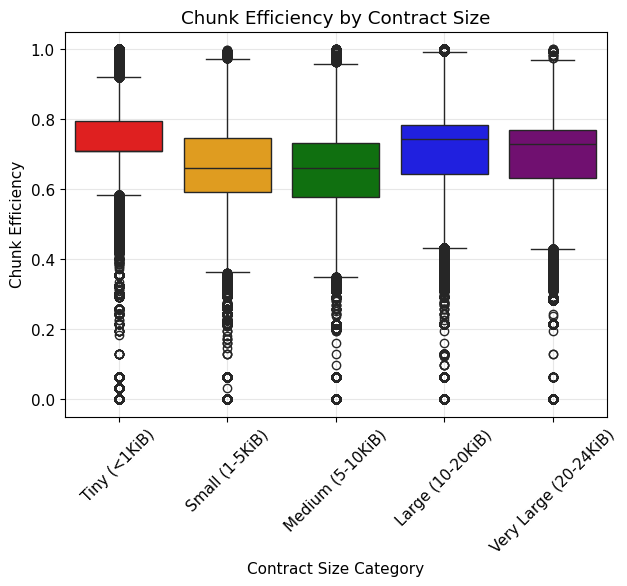
Core Finding: On average, 68.9% of the bytes in the 31-byte chunks were accessed. That’s roughly 21 bytes in every 31-byte chunks on average.
This indicates that more than half of the bytes in 31-byte chunks were accessed. To maximize chunk efficiency, we may consider smaller chunk sizes (e.g., 16-byte chunks). However, this comes at the cost of increased hashing overhead.
Code-Access Instructions
This section evaluates the impact of opcodes that access the entire code, namely:
EXTCODESIZEEXTCODECOPYCODECOPYCODESIZE
When one of these opcodes is executed, it requires access to all of the bytes in the bytecode. In the past sections of evaluating the access ratios, we exclude them from the results. Here, we assess how including them changes the access ratios. We split them into two categories:
- Code Size (
EXTCODESIZE,CODESIZE) - Code Copy (
EXTCODECOPY,CODECOPY)
The reason for the 2 categories is because EIP2926 adds the code size in the account field. Therefore, once it’s implemented, code size opcodes will no longer require access to the entire bytecode.

In total, 46.6% of contracts per block contain either the code size or code copy opcodes. Among these, 40.7% contain code size opcodes, while only 10.6% contain the code copy opcodes.
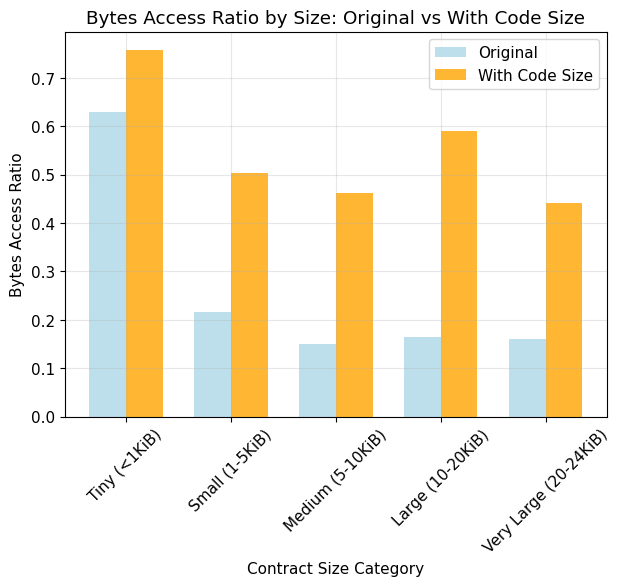
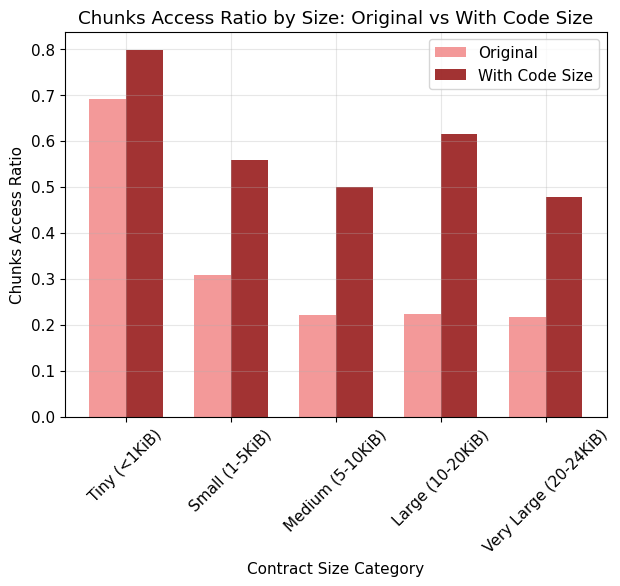
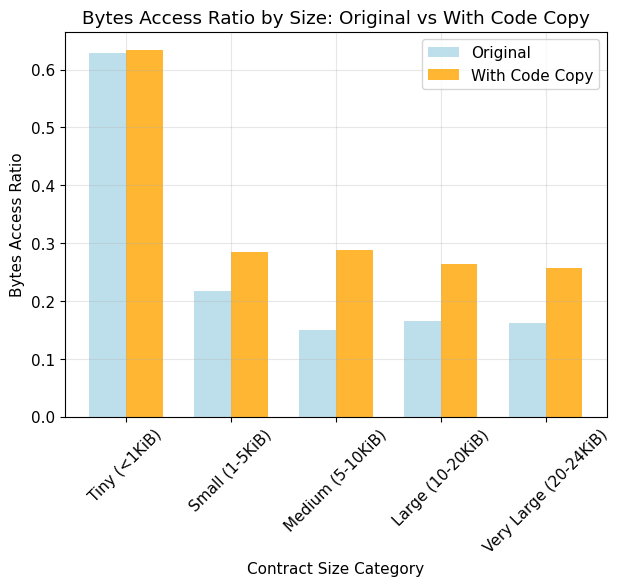
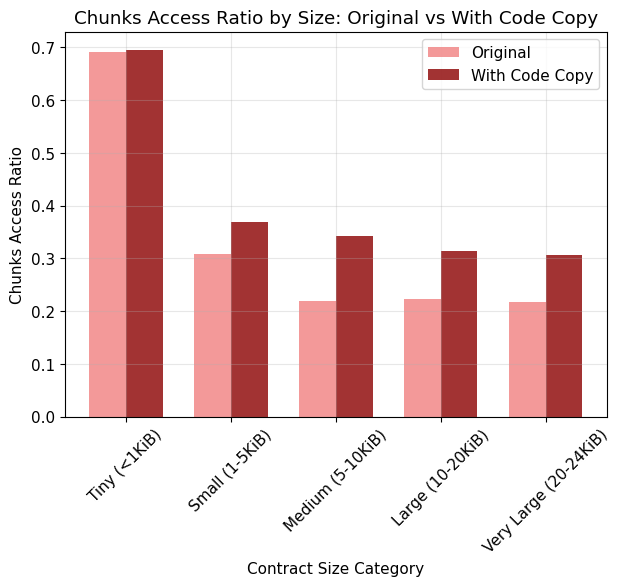
Avg Bytes Access Ratio
- Original: 22.8%
- With Code Size: 54.0% (+31.2%)
- With Code Copy: 31.5% (+8.7%)
Avg Chunks Access Ratio
- Original: 29.6%
- With Code Size: 57.8% (+28.2%)
- With Code Copy: 37.6% (+8.0%)
After including the code-access instructions, we do see a moderate increase in the access ratios. However, it’s mostly due to code size opcodes. As mentioned before, the addition of code size in the account field would make code copy opcodes the only instructions to access the entire bytecode. Since the amount of code copy instructions is significantly lesser, the overall access ratios are lower.
Is Code Chunking A Viable Solution?
Referencing EIP-2926, the main point of code chunking is to reduce witness size, as the current status quo requires the whole bytecode to be used in the code proof.
Our analysis has shown that not all of the bytes in a contract’s bytecode are used. In fact, only a relatively small proportion of the bytes and chunks are used. Based on the current access patterns, if we were to implement code chunking, we would significantly reduce the amount of actual bytes used included in the code witness.
The addition of code size in the account field in EIP2926 would effectively make code copy opcodes the only instructions that requires accessing the entire bytecode. In addition, as shown in our findings, the amount of code copy opcodes is significantly less than the code size. Therefore, we would further reduce the average code witness size based on the current access pattern.
One additional exploration that we can conduct is to determine the optimal chunk size. In EIP-2926, it uses 31-byte chunks. We may want to explore smaller chunk sizes, such as 16-byte, to maximize the number of bytes utilized per chunk. However, this comes at a cost of additional hash overhead. Therefore, we need to experiment with different chunk sizes to find the optimal balance.