


[Introduction] The volume is crazy! Groq, the world's fastest large model, became popular overnight and can output nearly 500 tokens per second. Such a fast response is all due to the self-developed LPU.
When I woke up, the Groq model that could output 500 tokens per second flooded the entire network.
It can be called "the fastest LLM in the world"!
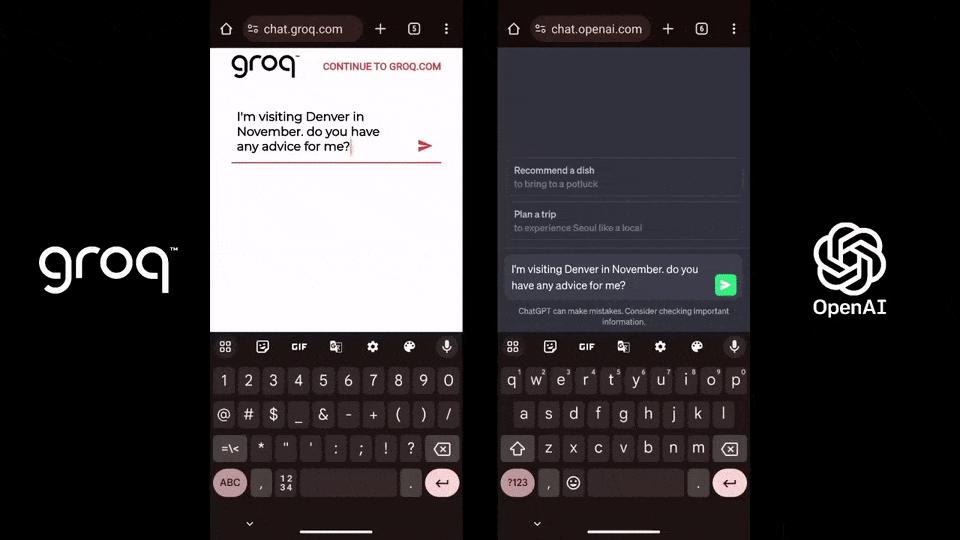
In comparison, ChatGPT-3.5 generates only 40 tokens per second.
Some netizens compared it with GPT-4 and Gemini to see how long it takes them to complete a simple code debugging problem.
Unexpectedly, Groq completely crushed the two, with an output speed 10 times faster than Gemini and 18 times faster than GPT-4. (But in terms of answer quality, Gemini is better.)
The most important thing is that anyone can use it for free!
Enter the Groq homepage, and there are currently two models you can choose from: Mixtral8x7B-32k and Llama 270B-4k.
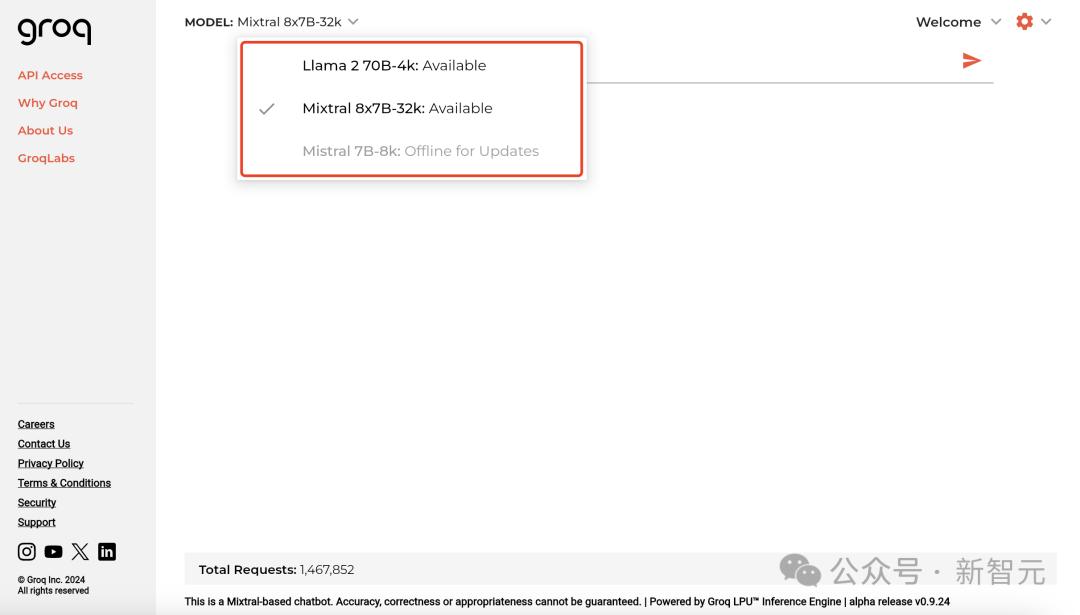
Address: https://groq.com/
At the same time, Groq API is also provided to developers and is fully compatible with OpenAI API.
Mixtral 8x7B SMoE can reach 480 token/S, and the price of 1 million tokens is US$0.27. In extreme cases, Llama2 7B can even achieve 750 token/S.
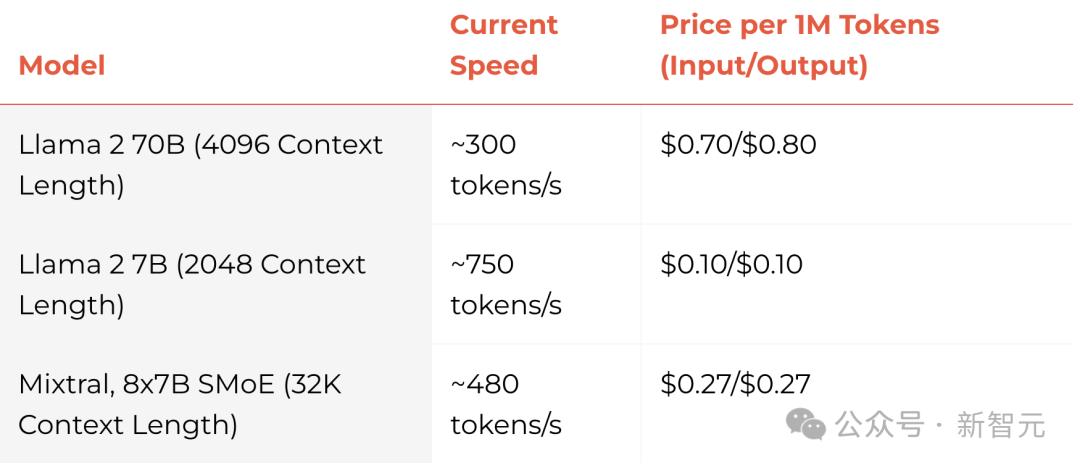
Currently, they also offer a free trial of 1 million tokens.
Groq suddenly became popular. The biggest contributor behind it was not the GPU, but the self-developed LPU - language processing unit.
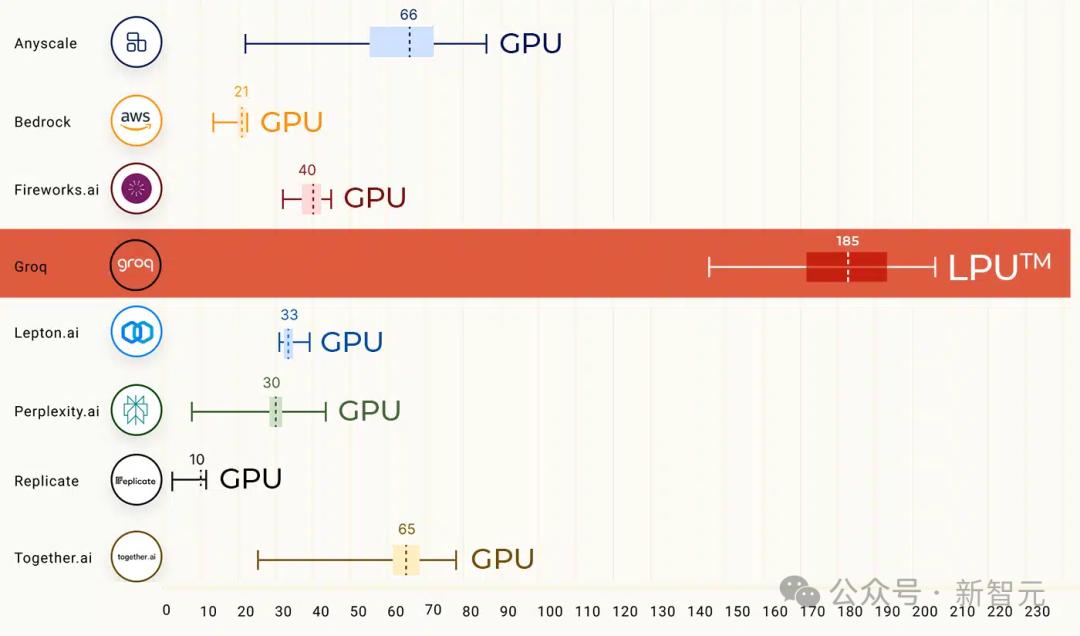
A single card has only 230MB of memory and costs $20,000. On LLM tasks, the LPU is 10 times faster than NVIDIA's GPU performance.

In a benchmark test some time ago, Llama 2 70B running on the Groq LPU inference engine directly topped the list, and its LLM inference performance was 18 times faster than the top cloud providers.
Demonstration by netizens
Groq's rocket-like generation speed shocked many people.
Netizens have released their own demos.
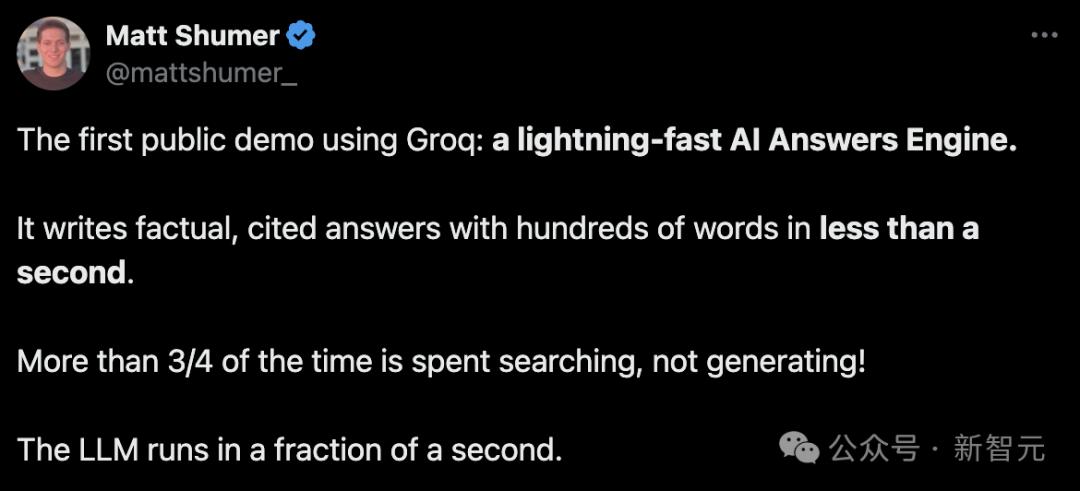
Generate hundreds of words of factual answers with quotes in less than a second.
In fact, search takes up more than three-quarters of processing time, not content generation!
For the same prompt "Create a simple fitness plan", Groq and ChatGPT responded side by side, with different speeds.

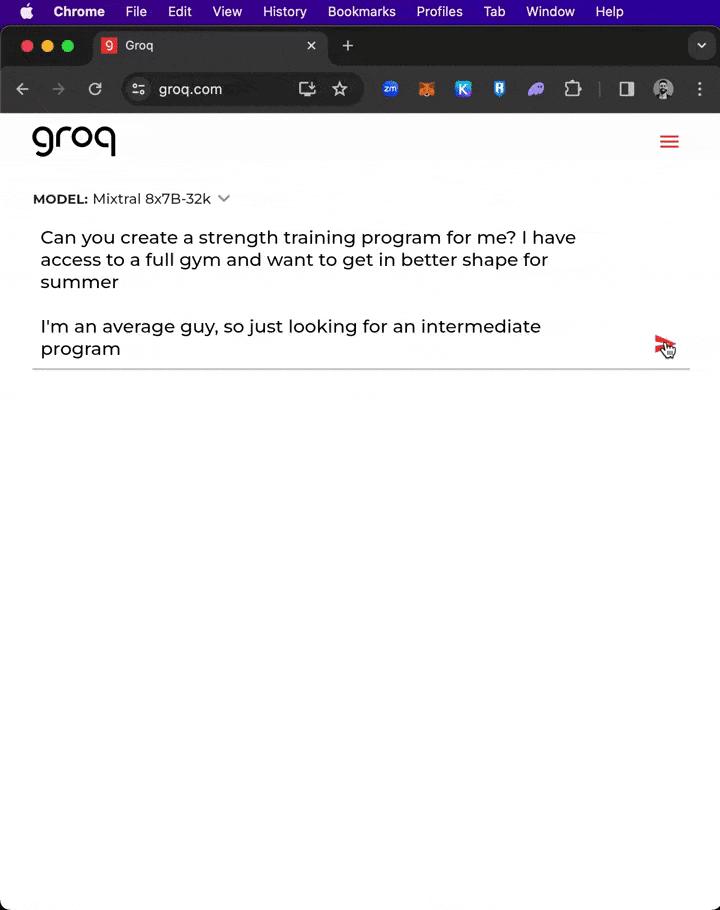
Faced with a "giant" prompt of more than 300 words, Groq created a preliminary outline and writing plan for a journal article in less than a second!

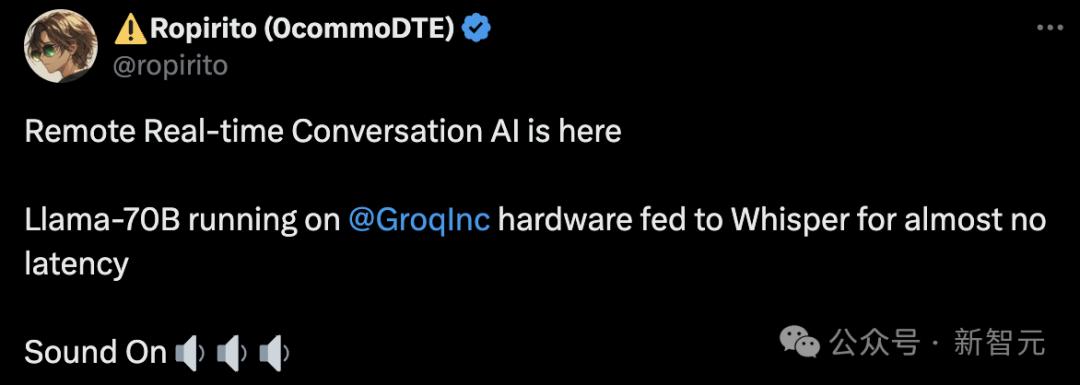
Groq fully realizes remote real-time AI dialogue. Running the Llama 70B on GroqInc hardware and then feeding it to Whisper, there was virtually no lag.
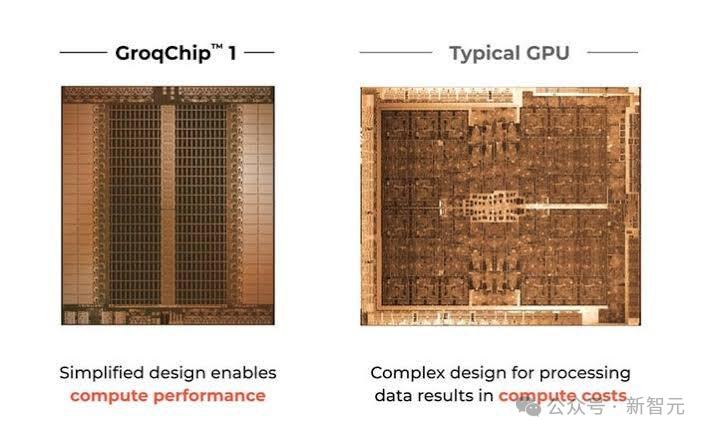
GPU no longer exists?
The reason why the Groq model is so responsive is because the company behind it, Groq (of the same name), has developed a unique piece of hardware called the LPU.
Not, traditional GPU.

In short, Groq self-developed a new type of processing unit called the Tensor Flow Processor (TSP), and defined it as a "Language Processing Unit", or LPU.
It is a parallel processor designed specifically for graphics rendering and contains hundreds of cores, which can provide stable performance for AI calculations.

Paper address: https://wow.groq.com/wp-content/uploads/2024/02/GroqISCAPaper2022_ASoftwareDefinedTensorStreamingMultiprocessorForLargeScaleMachineLearning.pdf
Specifically, the LPU works very differently from the GPU.
It uses a Temporal Instruction Set Computer architecture, which means it doesn't need to load data from memory as frequently as a GPU using high-bandwidth memory (HBM).
This feature not only helps avoid HBM shortages, but also effectively reduces costs.
This design enables every clock cycle to be effectively utilized, thus ensuring stable latency and throughput.
In terms of energy efficiency, LPU also shows its advantages. By reducing the overhead of multi-thread management and avoiding underutilization of core resources, LPU is able to achieve higher computing performance per watt.
Currently, Groq supports a variety of machine learning development frameworks for model inference, including PyTorch, TensorFlow and ONNX. However, using the LPU inference engine for ML training is not supported.
Some netizens even said, "Groq's LPU is faster than NVIDIA's GPU in processing requests and responses."

Unlike Nvidia GPUs, which rely on high-speed data transfer, Groq's LPU does not use high-bandwidth memory (HBM) in its system.
It uses SRAM, which is about 20 times faster than the memory used by GPUs.
In view of the fact that the amount of data required for AI inference calculations is much smaller than that for model training, Groq's LPU is therefore more energy-efficient.
It reads less data from external memory and consumes less power than Nvidia's GPUs when performing inference tasks.
LPU does not have extremely high requirements on storage speed like GPU.
If Groq's LPU is used in AI processing scenarios, there may be no need to configure special storage solutions for Nvidia GPUs.

Groq's innovative chip design enables seamless linking of multiple TSPs, avoiding common bottlenecks in GPU clusters and greatly improving scalability.
This means that as more LPUs are added, performance can be scaled linearly, simplifying the hardware requirements for large-scale AI models and making it easier for developers to expand applications without rebuilding the system.

Groq claims that its technology can replace the role of GPUs in inference tasks through its powerful chips and software.
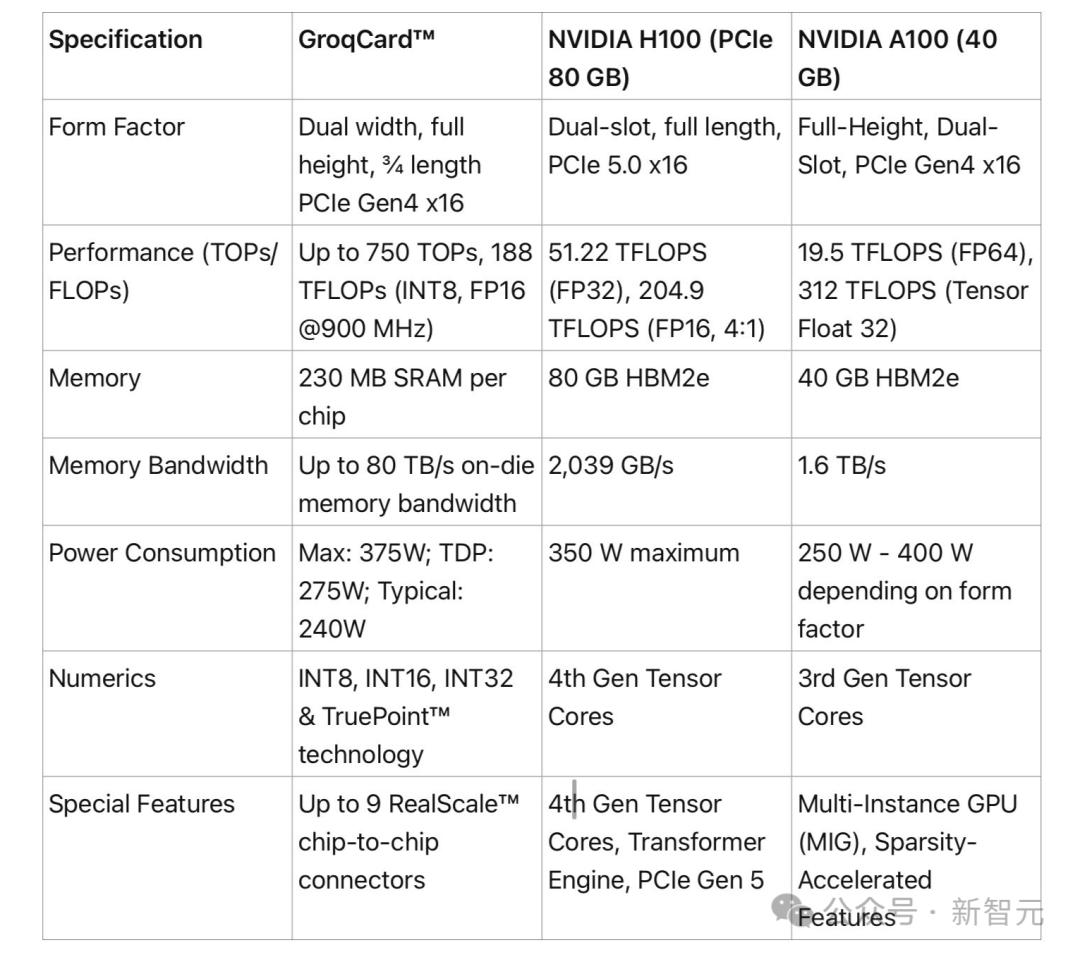
Specific specifications comparison chart made by netizens.
What does this all mean?
For developers, this means performance can be accurately predicted and optimized, which is critical for real-time AI applications.
For future AI application services, LPU may bring huge performance improvements compared to GPU!
Considering that the A100 and H100 are in such short supply, having such high-performance alternative hardware is a huge advantage for startups.
Currently, OpenAI is seeking US$7 trillion in funding from global governments and investors to develop its own chips and solve the problem of insufficient computing power when expanding its products.

2 times the throughput, response speed is only 0.8 seconds
Some time ago, in ArtificialAnalysis.ai's LLM benchmark test, Groq's solution defeated 8 key performance indicators.
These include latency vs. throughput, throughput over time, total response time, and throughput variance.
In the green quadrant in the lower right corner, Groq achieved the best results.
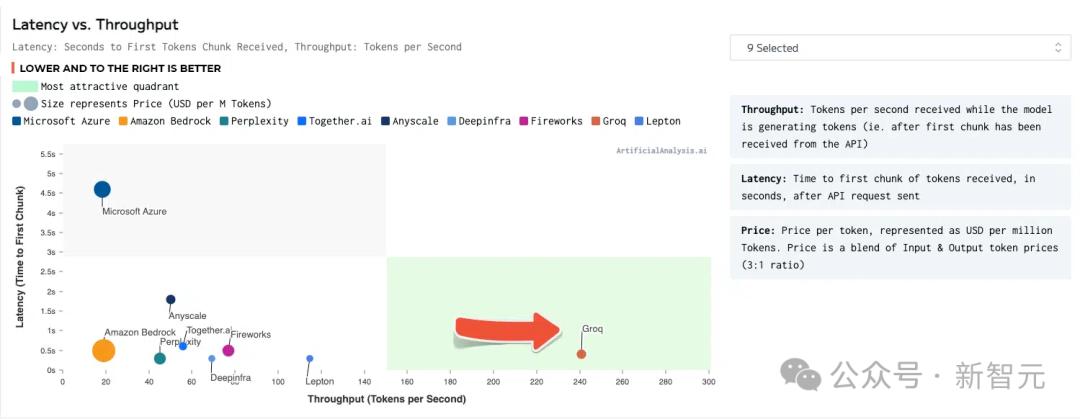
Source: ArtificialAnalysis.ai
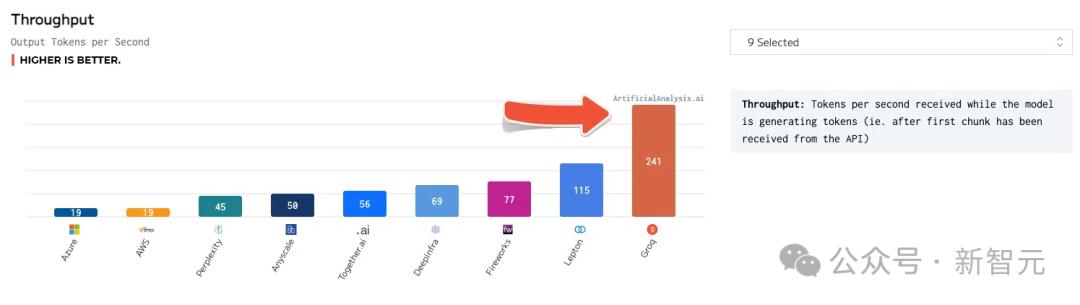
Llama 2 70B has the best performance on the Groq LPU inference engine, reaching a throughput of 241 tokens per second, which is more than twice that of other major manufacturers.
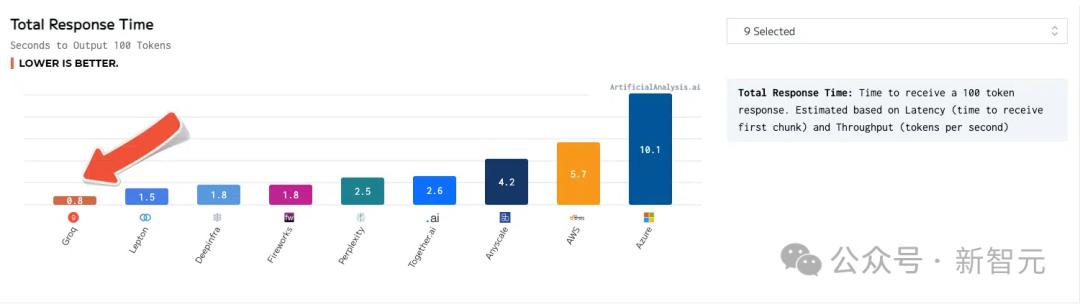
total response time
Groq's response time is also the lowest, with only 0.8 seconds for output after receiving 100 tokens.
In addition, Groq has run several internal benchmarks and can reach 300 tokens per second, once again setting a new speed standard.
Groq CEO Jonathan Ross once said, “Groq exists to eliminate the ‘haves and have-nots’ and help everyone in the artificial intelligence community develop. "Inference is key to achieving this goal, because speed is the key to turning developer ideas into business solutions and transforming apps."

A card costs $20,000 and has 230MB of memory.
You must have noticed before that an LPU card only has 230MB of memory.

And, the price is $20,000+.

According to The Next Platform, in the above test, Groq actually used 576 GroqChip to achieve Llama 2 70B inference.

Generally speaking, GroqRack is equipped with 9 nodes, 8 of which are responsible for computing tasks, and the remaining 1 node is used as a backup. But this time, all nine nodes were used for computing work.

Netizens said that a key problem faced by Groq LPU is that they are not equipped with high-bandwidth memory (HBM) at all, but only equipped with a small piece (230MiB) of ultra-high-speed static random access memory (SRAM). SRAM is 20 times faster than HBM3.
This means that in order to support running a single AI model, you need to configure approximately 256 LPUs, which is equivalent to 4 fully loaded server racks. Each rack can accommodate 8 LPU units, and each unit contains 8 LPUs.
By comparison, you only need one H200 (density equivalent to 1/4 of a server rack) to run these models fairly efficiently.
This configuration may work well if you only need to run a single model and have a large number of users. However, this configuration is no longer suitable once multiple models need to be run simultaneously, especially when extensive model fine-tuning or high-level LoRA operations are required.
In addition, for situations where local deployment is required, the advantage of this configuration of Groq LPU is not obvious, because its main advantage is the ability to centralize multiple users to use the same model.
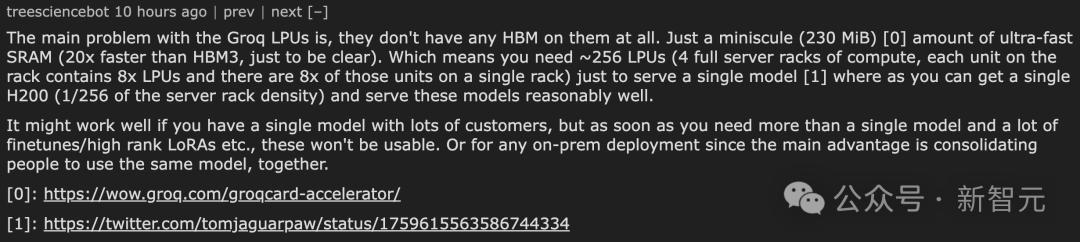
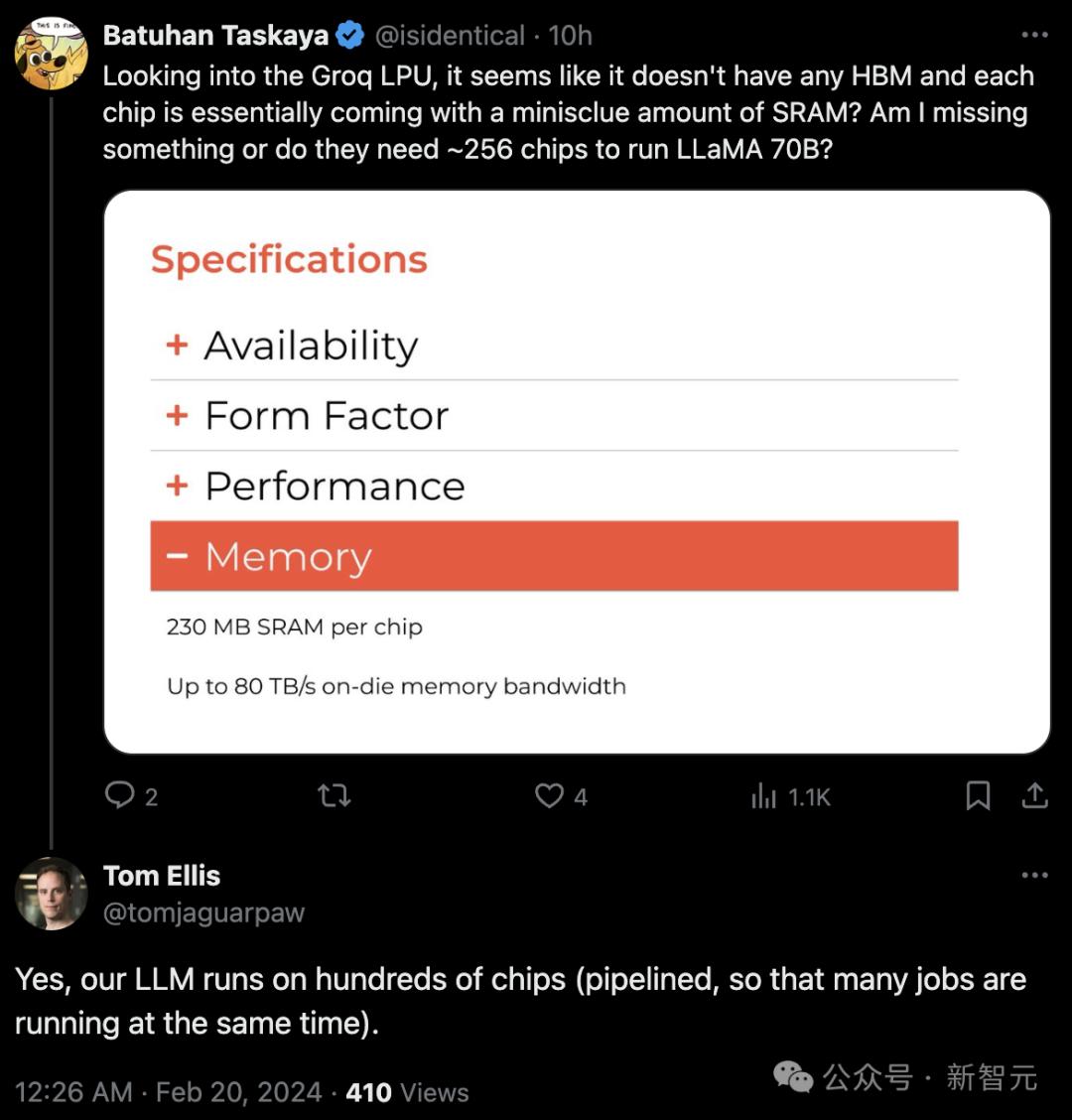
Another netizen said, "Groq LPU doesn't seem to have any HBM, and each chip basically comes with a small amount of SRAM? Does that mean they need about 256 chips to run Llama 70B?"
Unexpectedly, I got an official response: Yes, our LLM runs on hundreds of chips.
Others have raised objections to the price of LPU cards, "Wouldn't this make your product ridiculously more expensive than the H100?"

Musk Grok, same pronunciation but different words
Some time ago, Groq attracted a lot of attention after publishing the benchmark results.
This time, Groq, the latest AI model, has once again set off a storm on social media with its fast response and new technology that may replace GPUs.
However, the company behind Groq is not a new star after the big model era.
It was founded in 2016 and directly registered the name Groq.

CEO and co-founder Jonathan Ross was a Google employee before founding Groq.
In a 20% project, he designed and implemented the core elements of the first-generation TPU chip, which later became the Google Tensor Processing Unit (TPU).
Subsequently, Ross joined the rapid evaluation team of Google X Labs (the initial stage of the famous "Moonshot Factory" project) to design and incubate new Bets (units) for Google parent company Alphabet.

Perhaps most people are confused by the names of Musk’s Grok and Groq models.

In fact, there was an episode when trying to persuade Musk to use this name.
Last November, when Musk's eponymous AI model Grok (spelled differently) began to gain attention, Groq's development team published a blog humorously asking Musk to choose another name:
We understand why you'll like our name. You have a soft spot for fast things (like rockets, hyperloop, one-letter company names), and our Groq LPU inference engine is the fastest way to run LLM and other generative AI applications. But we still have to ask you to change your name quickly.

However, Musk did not respond to the similarity in the names of the two models.
References:
https://x.com/JayScambler/status/1759372542530261154?s=20
https://x.com/gabor/status/1759662691688587706?s=20
https://x.com/GroqInc/status/1759622931057934404?s=20
This article comes from the WeChat public account "Xin Zhiyuan" (ID: AI_era) , editor: Tao Zi is so sleepy, and 36 Krypton is published with authorization.



