

Those who have used the DeepSeek-R1 model are familiar with its thinking process before providing answers, which is one of the reasons why Large Reasoning Models (LRM), including DeepSeek-R1, are highly regarded.
However, a team of six Apple researchers has challenged this notion. By having the model solve various puzzles, the research team discovered that advanced Large Reasoning Models like DeepSeek-R1, o3-mini, and Claude-3.7-Sonnet-Thinking experience a comprehensive accuracy collapse after exceeding a certain complexity threshold.

Figure | Related Paper (Source: https://ml-site.cdn-apple.com/papers/the-illusion-of-thinking.pdf)
Notably, Samy Bengio, Apple's Senior Director of Machine Learning Research, is a co-author of this paper. He is not only the brother of Turing Award winner Yoshua Bengio but also was one of the early members of the Google Brain team.

Figure | Six authors of the related paper, with Samy Bengio second from the right (Source: Reference Image)
A user on X summarized that Apple has played the role of Gary Marcus, and Gary Marcus himself actually affirmed this paper on LinkedIn. He wrote: "Apple's latest paper on 'reasoning' in large language models is quite shocking. I explained the reasons in a weekend long-form article (and explored a possible counterargument) to show why everyone shouldn't be too surprised."
In Gary Marcus's "weekend long-form article"he wrote: "This new paper from Apple further substantiates my critique: Even the latest developed so-called 'reasoning models' that have iterated beyond the o1 version still cannot achieve reliable out-of-distribution reasoning in classic problems like the Tower of Hanoi.For researchers hoping that 'reasoning capabilities' or 'reasoning computation' would get large language models back on track and break free from mere scale expansion (which has consistently failed to produce a breakthrough worthy of the 'GPT-5' name), this is undoubtedly bad news."

Figure | Gary Marcus's "weekend long-form article" posted on his personal website (Source: https://garymarcus.substack.com/p/a-knockout-blow-for-llms)
So, is this "bad news" or "good news"? Let's start with the details of Apple's paper.
[The translation continues in the same manner for the rest of the text, maintaining the structure and translating all text outside of XML tags.](3) Relying only on explicitly given rules, emphasizing algorithmic reasoning capabilities;
(4) Supporting simulator-based strict evaluation, enabling precise solution verification and detailed failure analysis.
Through empirical research, they revealed several key findings about current large reasoning models:
First, although large reasoning models can learn complex self-reflection mechanisms through reinforcement learning, they fail to develop generalizable problem-solving abilities for planning tasks, with performance dropping to zero beyond a certain complexity threshold.
Secondly, the research team's comparison of large reasoning models and standard large models under equivalent reasoning computations revealed three different reasoning mechanisms.
The first mechanism is: for simpler, less combinatorial problems, standard large models demonstrate higher efficiency and accuracy.
The second mechanism is: as problem complexity moderately increases, large reasoning models gain an advantage.
The third mechanism is: when problems become complex with increasing combinatorial depth, both model types experience a complete performance collapse.
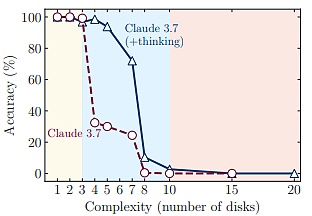
(Source: Reference Image)
Notably, approaching this failure critical point, although large reasoning models are far from reaching generation length limits, they begin to reduce reasoning investment (measured by Token count during reasoning) as problem complexity increases.
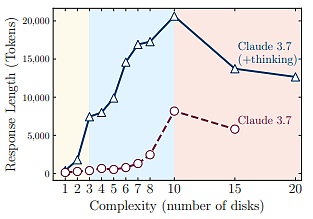
(Source: Reference Image)
This indicates a fundamental limitation of large reasoning models: their reasoning time significantly increases with problem complexity.
Moreover, through analysis of intermediate reasoning trajectories, the research team discovered regularity phenomena related to problem complexity: in simpler problems, reasoning models often quickly findincorrect solutions, yet inefficiently continue exploring incorrect options, a phenomenon commonly referred to as "overthinking".
In problems of moderate complexity, models require extensive exploration of numerous error paths before finding the correct solution. Beyond a certain complexity threshold, models completely fail to find the correct solution.






