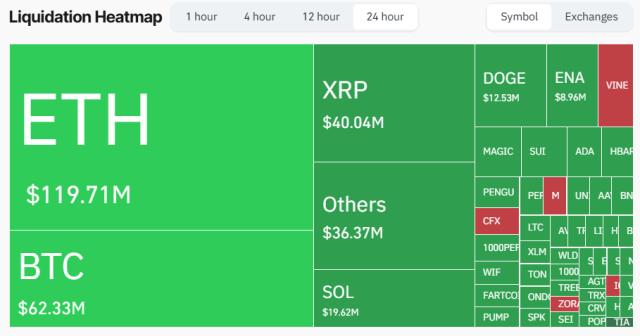
Open AI Open Source Model Information Leaked! This is an operating system series model with the smallest parameter of 20B and the largest parameter of 120B. The model's configuration file has also been leaked: MoE Transformer: 36 layers, 128 experts, Top-4 routing Attention: 64 attention heads, 64 dimensions per head; GQA Total parameters (sparse total) ≈ 116B Training/Base context length: initial_context_length: 4096 RoPE Long context extension: can expand available context to about 4096×32 ≈ 131k tokens Sliding window attention: sliding_window: 128 means primarily using a local attention window of 128 KV cache occupation: approximately 72 KB/token for K+V elements per layer per token. GQA has significantly reduced occupation. Summary: A large-scale sparse MoE model (total parameters ~116B, active ~5.1B) with long context (around 128k level, with NTK RoPE), using GQA + sliding window attention to reduce memory and computation; attention projection wider than hidden dimension to increase capacity. Suitable for high throughput and long text scenarios, with optimal KV overhead and parallel characteristics on the decoding side.
This article is machine translated
Show original

Jimmy Apples
@acc
So before people take credit, I found the oai os a min after they uploaded and saved the config and other stuff before it was removed.
It’s an OS model and coming soon so kinda feels like ruining a surprise
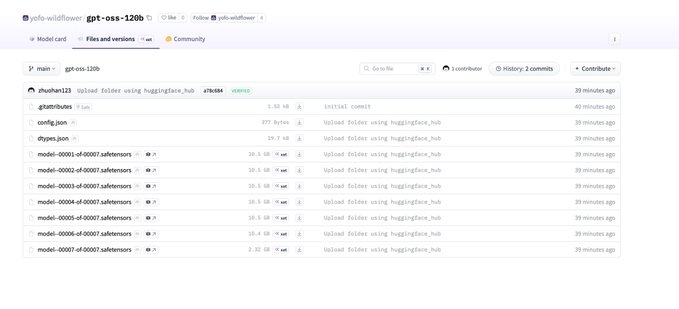
From Twitter
Disclaimer: The content above is only the author's opinion which does not represent any position of Followin, and is not intended as, and shall not be understood or construed as, investment advice from Followin.
Like
Add to Favorites
Comments
Share